
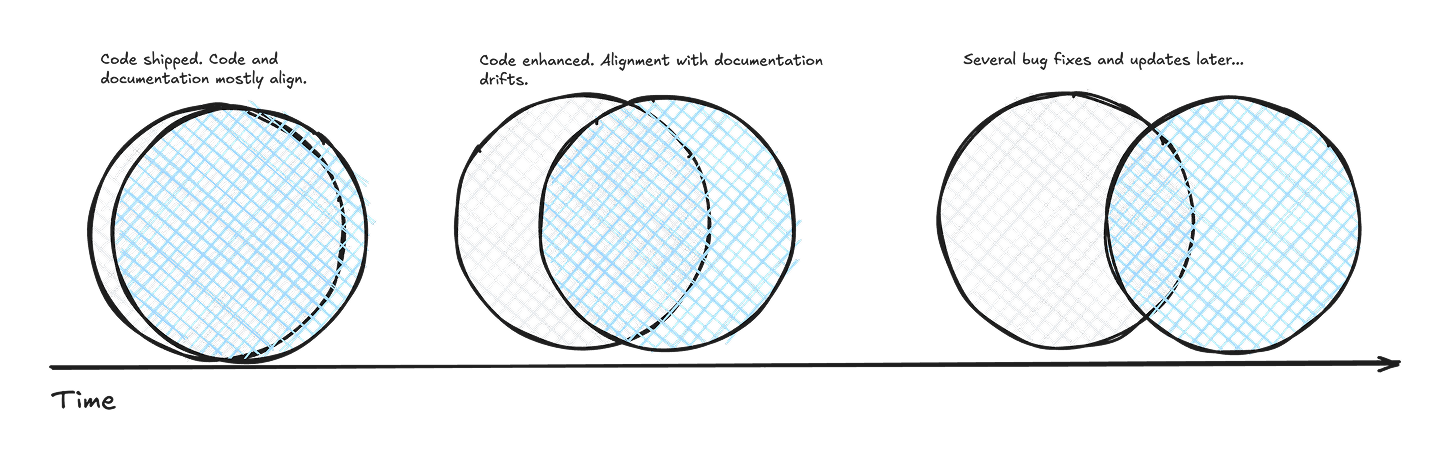
This happens everywhere:
You write code. You write a help article about your code. You ship your code. Your code gets used. It has a bug. You fix it. Users ask for your code to do more. You make it do more.
Now your help article is only partially aligned with your code.
A customer asks Support about your code. A prospect asks Sales about your code. Nobody trusts the help article. So they ask you to answer the question about your code.
You’re now a bottleneck. Boo.
Or.
Somebody else wrote code years ago. Another person added to it before you joined the company. Both people are gone.
The help article about the code is three years old. Nobody trusts it.
A customer asks Support about the code. A prospect asks Sales about the code. They ask you to answer the question about the code.
You’re once again a bottleneck.
Code and documentation are in a constant state of micro-drift. Every software update makes documentation a little less aligned with the code. Some organizations hire technical writers to keep up. This is sometimes successful. But, eventually, most organizations stop trusting their documentation. Once they find one discrepancy, they assume discrepancies are everywhere.
But what if we could use our code as the basis for product answers? If the code is always true, wouldn’t our answers always be true, too?
BonuslyGPT
AI is insanely good at understanding code. Here at Bonusly, we asked ourselves the question, “What if we could build an AI agent that understands our codebase, like a tenured engineer, and uses that knowledge to answer product questions?”
So we built BonuslyGPT and rolled it out last month. It’s an AI agent that Bonusly employees interface with via Slack.
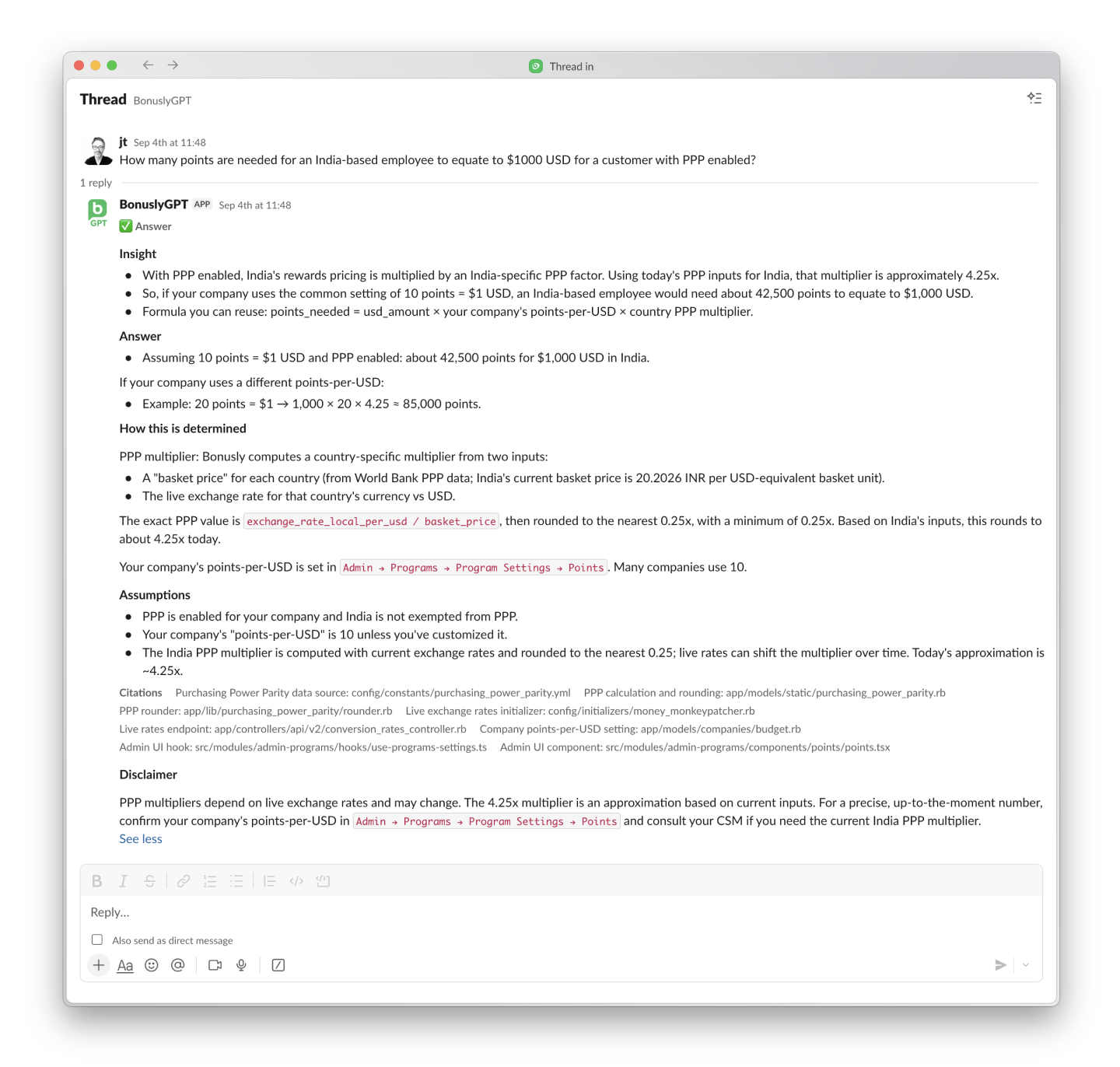
Here’s how it works.
A picture
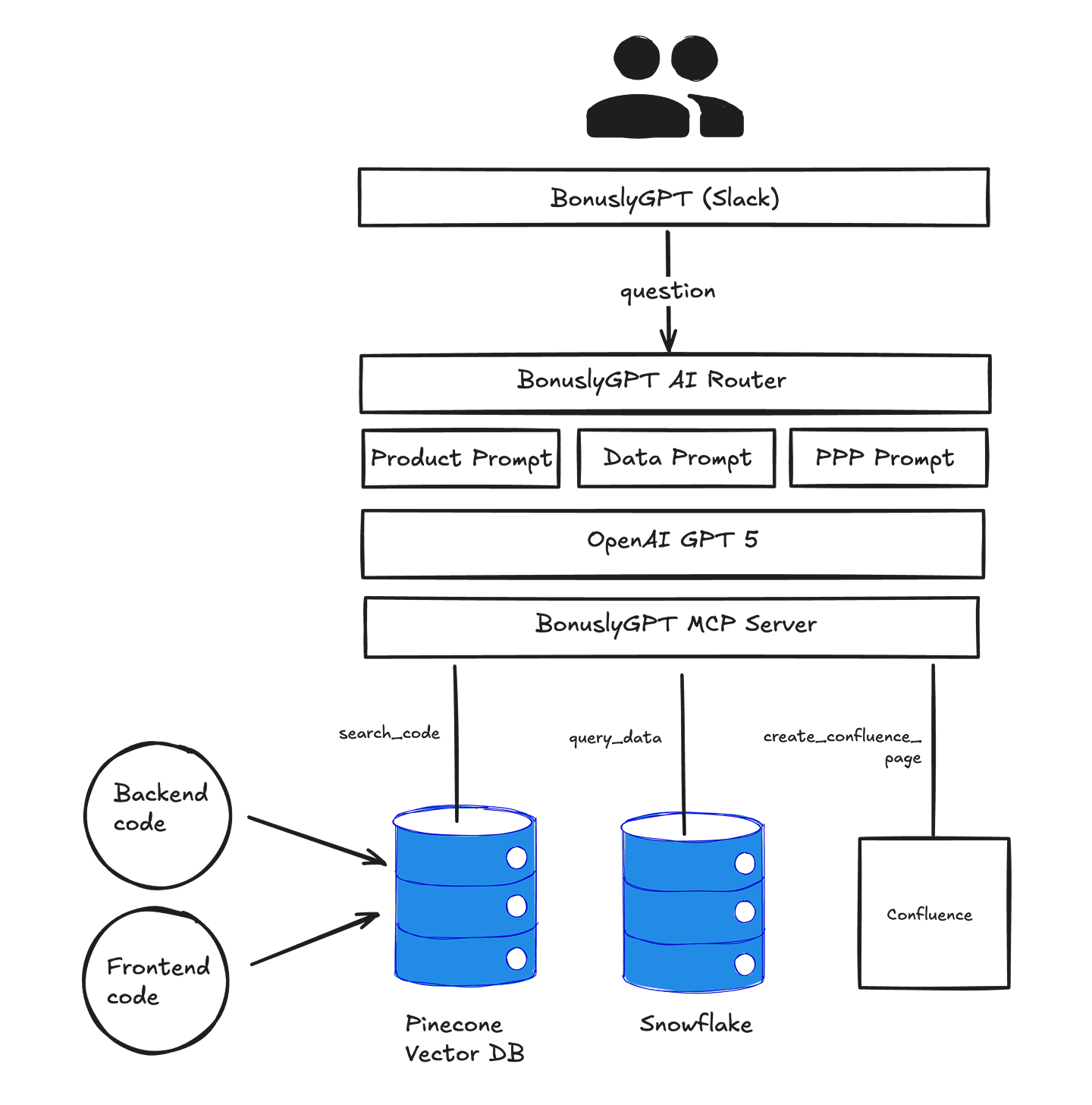
BonuslyGPT is a multi-modal agent. The first layer is an AI router that determines which prompt is best suited to answer the user’s question. Today we have three prompts; one that specializes in answering questions about product functionality, another that answers data-oriented questions, and a third that answers purchase-power parity (PPP) questions (a nuanced feature inside Bonusly that uses basket prices and exchange rates to distribute rewards budgets equitably across employees in multi-national companies).
All three prompts sit on top of OpenAI’s GPT-5 model.
Access to our code
But the real magic comes with how we’ve approached giving BonuslyGPT access to our source code. And in order to understand why the magic is magical, we should first contemplate how we would have built this thing back when RAG was the “it” thing. (Pay special attention to the green circle):
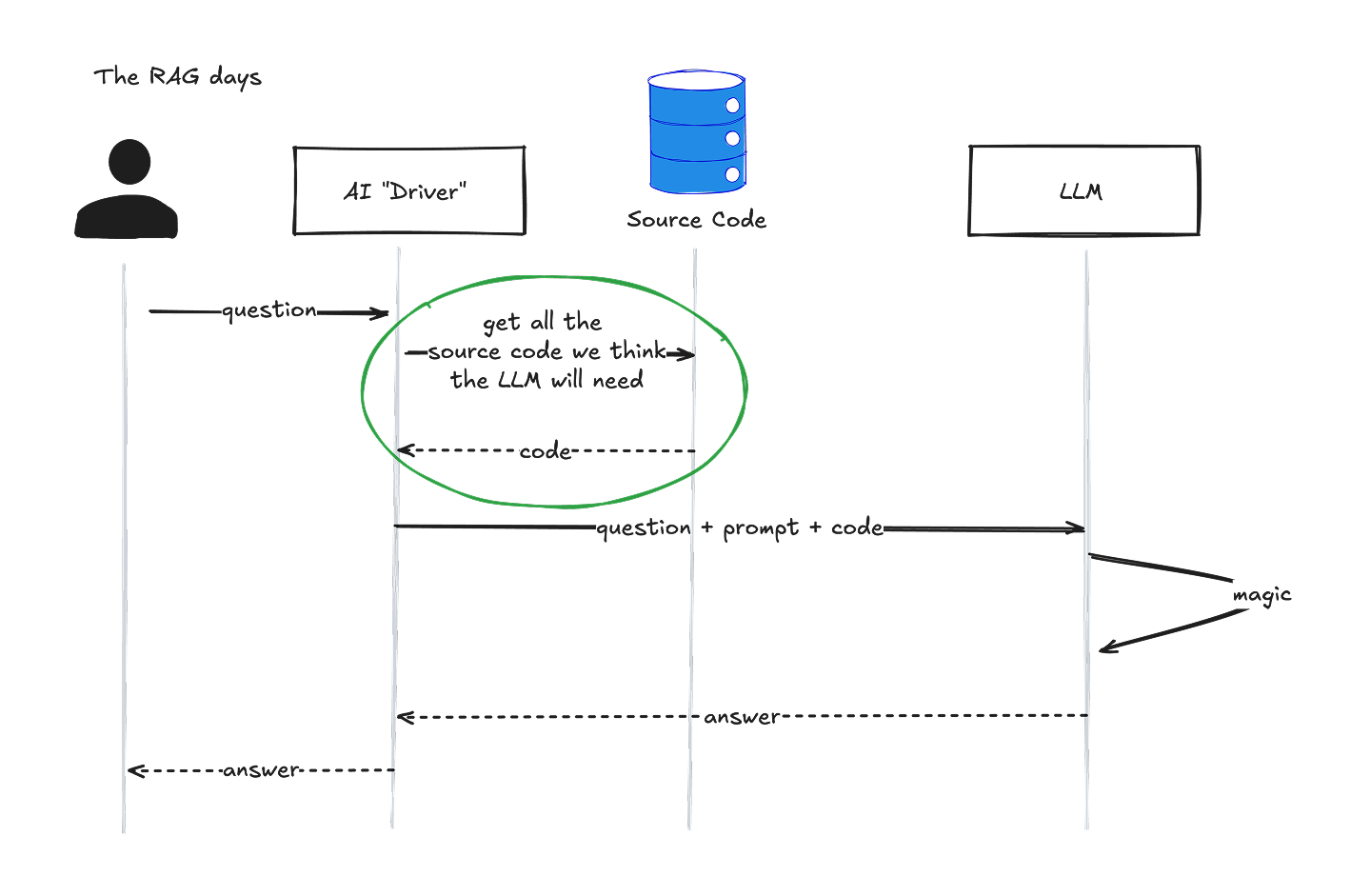
The AI Driver, which is “the program that receives the user’s question and has the AI prompt,” would have retrieved all of the source code it thought the LLM would need to answer the question. Then it would have passed all of it, along with the prompt and the user’s question, to the LLM. It was a bit of a single-shot, i-hope-you-find-the-answer-somewhere-in-here approach.
Meh.
Well, ok, “meh” is harsh. One of the cool things we borrowed from the RAG approach is that we could use the same embeddings magic that makes AI great with our own source-code data. RAG enthusiasts advocate a process where proprietary data (i.e. the content of each source-code file) is converted into embeddings, then stored as a vector in a vector DB index. When the user asks a question, we convert the question into an embedding using the same algorithm, then ask the vector DB to return vectors, er source-code files, that are semantically related to the question.
Rad.
When we built BonuslyGPT, we took the part of RAG that was, well, rad, and mashed it up with MCP. Our objective was to defer to the LLM’s reasoning process to retrieve the source code it needs as it learns how to answer the question. We believed the LLM would be able to get more specific data and deliver great answers with it.
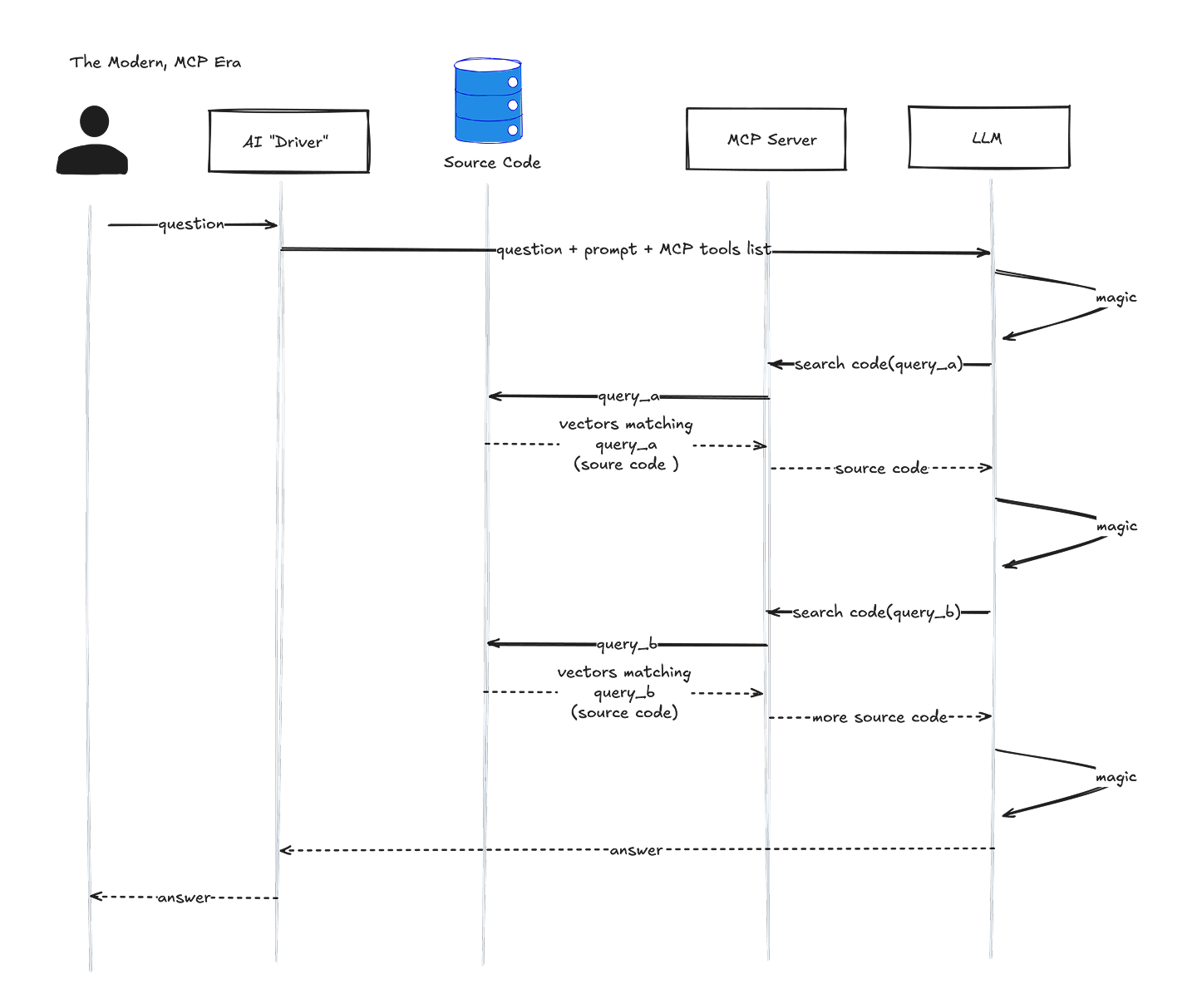
So the biggest difference here is that source-code data isn't delivered by the driver to the LLM. Instead, the prompt instructs the LLM to retrieve the code it needs through our MCP server during the reasoning process. When we watch the log files, we see it ask for code matching very specific query parameters as it gets closer and closer to the answer. I’ve illustrated only two turns on the MCP server here. But sometimes it can make dozens of turns before coming up with an answer.
The prompt
I know what you’re thinking. This can get out of hand. What prevents the LLM from making infinite tool calls and exploding its context window? This is where prompt engineering plays a role.
Our product questions prompt begins like this:
You are BonuslyGPT, an expert software engineer and product analyst.
Answer product and functionality questions using ONLY code you fetch via the provided tools.
You have access to FULL FILE CONTENT for deep analysis of how features work.
…
# TOOL PLAYBOOK
search_code(query, top_k=5) - Get the list of relevant files. This tool returns complete file content for each file.
1. Use multiple searches to understand the complete functionality
2. Be thorough - up to 10 tool calls are acceptable for complex questions although you need to be mindful of your context window.
3. Use varied queries to explore different aspects of the functionality. Avoid identical repeated queries.
4. Once you have sufficient information, provide your final answer with citations.
5. If no relevant code is found, say "I don't know."
…
# RESPONSE
The user is not an engineer. Do not respond with references to code. Instead, respond in terms of product functionality that can be understood by Bonusly employees. The answer should be helpful and reference product functionality (not code) as its basis.
Cite the sources for your answer at the end of your response. Don't put them inline with your response as your sources will likely confuse non-engineers.
We found that that bit in the TOOL PLAYBOOK that says “up to 10 tool calls are acceptable for complex questions although you need to be mindful of your context window” does reasonably limit the number of tool calls. And importantly, the instructions to cite sources at the end have proved helpful in building trust in the system.
Results
Questions answered by BonuslyGPT since July:

We have around 70 employees. And we’re seeing an upward trend that today has us just over 20 questions answered per day. And these are the kinds of questions that would take an engineer ~20 minutes to answer (once they get to it) given the research that’s usually involved. So that’s about 6 hours of engineering research saved per day.
And then there’s the unquantified benefit of getting answers returned quickly to the people asking the questions. Time matters a lot when escalations happen, or when prospects have questions in the moment.
We’re happy with the results. Long live MCP!
AI at Bonusly
BonuslyGPT has a positive effect on how we work here at Bonusly. It’s an implementation detail that plays a role in how AI changes how we do our jobs. And much of what we learned building it informs how we incorporate AI into our product, too. Yes, every company is “doing AI” these days and claims their products are now AI-first.
But think about it; Bonusly is natural language. It’s people recognizing people with words.
The opportunity to use AI to help people be more human with each other, the opportunity to use AI to create insights from those words, is right in front of us. And we’re taking it.

.png)

